Well, after six days of a ketogenic diet and four with COVID symptoms, I can definitely say that my energy is depleted. As a card-carrying workaholic, it is an interesting opportunity to really ask myself:
What is the truly essential work that I need to do?
This is a question that I try to bring my attention to regularly, but there’s nothing like extremely low blood sugar and a COVID infection to get your priorities straight. Today, I’m just trying to do the work that is truly essential, and a bit of work that is easy/energizing: syncing up with my team on the plan for the week, sharing some new technical ideas that I have with our collaborators, making sure our insurance gets renewed on time.
I am walking and dictating this, walking very slowly because I’m feeling weak. It will only take a few minutes to turn the transcription into a blog post and social media posts.
Here are some resources that I’ve found helpful in asking this question of what is truly essential.
In my current workflow, I’m using webhooks with Make.com to send posts to Buffer. This is great for LinkedIn, X/Twitter, and Facebook Pages. Unfortunately, Meta makes it pretty rough for folks to post to personal Facebook profiles, Instagram, or Threads via API. As far as I can tell, these all require some sort of manual intervention.
Why webhooks? So I can post the content programatically. (Right now from a Jupyter notebook inside the same repo as this website, which I run in Cursor because I suck at programming and I am eagerly awaiting my AI overlords.)
So I don’t have to deal with the API’s of each platform.
So I can schedule posts without setting up cron jobs or intricate automation workflows.
So I can preview/schedule/share posts without actually logging into any of the platforms. (I might never come back if I do that.)
I used to be a big fan of Buffer, but they seem to have completely stopped listening to their users. To their credit, I think the social media apps make their lives pretty miserable.
When I find the time I’ll come up with a better solution. Let me know if you have any ideas.
I have COVID, for the second time. It’s not fun, but I’m doing 10x better than last time.
Big inflection point: Paxlovid. I got it within 24 hrs of testing positive, and it is clearly keeping everything in check. Horrible metallic taste in my mouth, but I’ll take it. I was initially very skeptical after hearing all of the stories of rebounds, but I gave it a shot after a few friends shared how quickly it helped them recover. Fingers crossed for no rebound or weird complications.
Activity: Slow walking, at least 10,000 steps a day. Sleep as much as possible at night and just let myself nap whenever I’m tired.
P.S. - I got GPT4V to make the list of these supplements from a single photo. Unfortunately, both Bing and ChatGPT refuse to find product links on Amazon. For that I had to switch to Bard, and then fix about half of them manually…oh well.
Well it erupted. (…and I sincerely hope that you didn’t quit your job to make custom GPTs for a living.)
A few people figured out how to trick the custom GPTs that are starting to roll out to the app store into revealing their prompt instructions.
The result is hands-down the most comprehensive and high quality repository of prompts that I have ever found:
https://github.com/linexjlin/GPTs
For additional context, many of these are “professionally-created”, bringing in thousands of dollars a month in revenue sharing to their creators. I’ve shared elsewhere that I think it’s a terrible idea to try to be selling AI products right now, this is case-in-point. It has a nice parallel with the “AI as electricity” riff - once you know how to do the magic trick, it’s pretty hard to keep other people from copying you! (and very quickly everyone will expect it to be essentially free.)
In this video, we go behind the scenes of the creation of the revolutionary new GPT, Human Instruct Turbo. This is unedited, unplanned, completely raw footage of creating a custom OpenAI GPT from start to finish. Watch me fumble so you don’t have to.
In this video, I delve into the world of AI transcription, specifically focusing on MacWhisper, a leading tool for AI-driven voice-to-text transcription on Mac. We explore how to enhance MacWhisper with a custom glossary for accurate transcription of unique words and proper nouns, and share tips from the OpenAI Cookbook to refine your MacWhisper settings.
I also demonstrate real-life application by adding custom product names to our vocabulary, troubleshoot common transcription mistakes using find-and-replace, and explore the benefits of using larger AI models for improved accuracy.
Whether for professional or personal use, MacWhisper adapts to your specific language needs, offering privacy-focused and highly accurate transcriptions.
There were a few interesting ideas on customizing generative AI for eCommerce. Unfortunately I think the OctoAI product still has a long way to go, I frankly was not impressed with the onboarding experience after getting amped up by this webinar.
But one quote stuck with me all day. It has nothing to do with AI:
Find something that you’re really passionate about, find something that you can become the best in the world at, and find something that you can make money doing.
I think this is fantastic advice for anyone, not just entrepreneurs. A trifecta of how to decide what to work on. (58:39 in the video)
Dalle3 made this diagram. I don't know what the symbol in the middle is, but I think you get the point.
The pace of AI development over the last few months has been simply exhausting. Exhilarating, but exhausting.
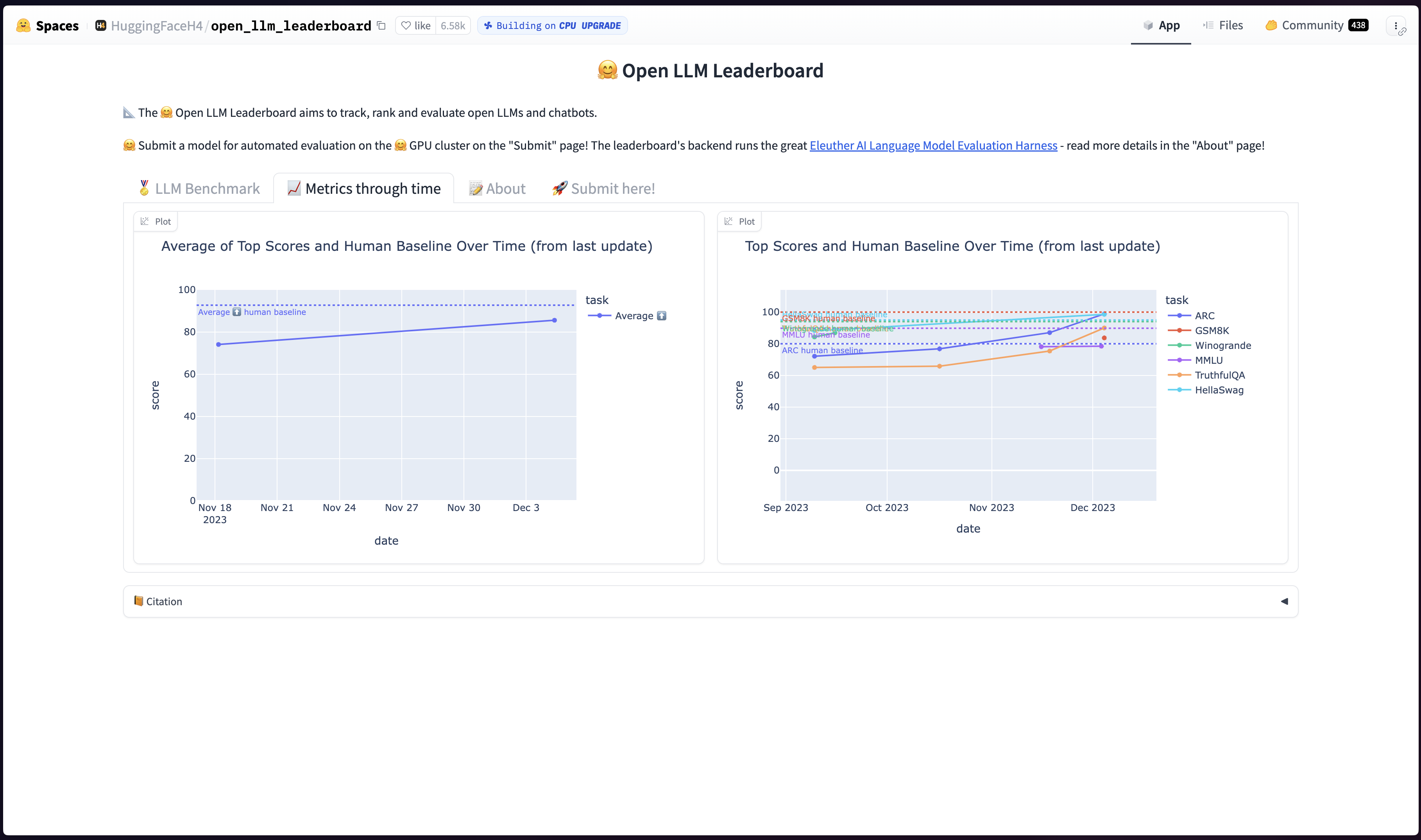
Just look at this chart. This is just the open source LLMs.
I don’t check this leaderboard very often, but the Mistral models that were winning two weeks ago aren’t even in the top 20.
Here’s some cool stuff I found since I ate dinner an hour ago. (Sorry, I literally don’t know what else to do…there’s too much cool stuff.)
WikiChat on GitHub: WikiChat enhances the factuality of large language models by retrieving data from Wikipedia.
LLMCompiler on GitHub: LLMCompiler is a framework for efficient parallel function calling with both open-source and close-source large language models.
Flowise on GitHub: Flowise offers a drag & drop user interface to build customized flows for large language models.
1/n Was December 8th, 2023, the day when we've come to realize that AGI technology has been democratized? That it cannot be confined to the few and the GPU-rich? Let me explain to you what happened yesterday. pic.twitter.com/syLBuCVqG6
The issue with basic RAG strategies (chunking, top-k), is that they’re fine with plain .txt essays, but they do terribly over complex documents - w/ embedded objects like tables, diagrams 📊, and hierarchical sections 🪆